
Capsules introduce a new building block that can be used in deep learning to better model hierarchical relationships inside of internal knowledge representation of a neural network. Intuition behind them is very simple and elegant.
Hinton and his team proposed a way to train such a network made up of capsules and successfully trained it on a simple data set, achieving state-of-the-art performance. This is very encouraging.
Nonetheless, there are challenges. Current implementations are much slower than other modern deep learning models. Time will show if capsule networks can be trained quickly and efficiently. In addition, we need to see if they work well on more difficult data sets and in different domains.
In any case, the capsule network is a very interesting and already working model which will definitely get more developed over time and contribute to further expansion of deep learning application domain.
https://arxiv.org/pdf/1710.09829... (paper from Hinton et al. proposing capsule networks in 2017).
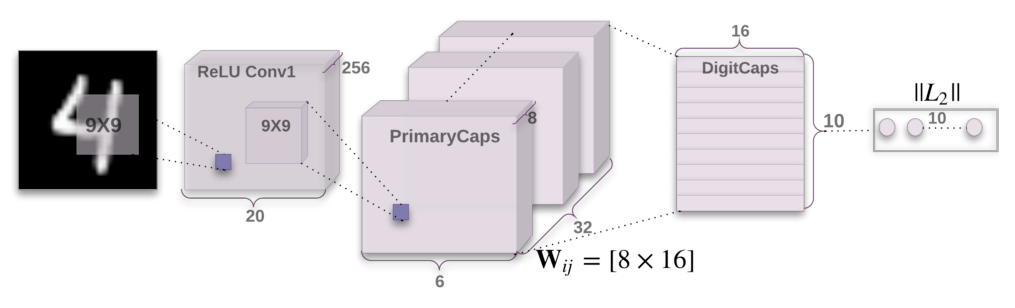
The main point is that while CNNs are great in recognizing both simple features in the lower layers of an image (edges and colors gradients), as well as their complex compositions in the deeper levels (ball, dog, cat, face, wheel, car …) - they do a very poor job in representing their rotational and translational relationships (meaning, how they are organized in space in respect to each other).
For example, a CNN might be very successful in recognizing the different elements of a face in an image - eyes, nose, mouth, and deduce that an image segment containing these - most probably represents a face. However, it will not be sensitive to the arrangement of the entities (mouth under nose, then two symmetric eyes above that), and might mistakenly recognize different arrangements of these entities also as face.
Hinton is especially critical of the mechanism that CNNs use to handle some translational invariance - the MaxPooling.
There are multiple consequences for this shortcoming, but two major ones are:
- Misclassification of images that contain the “right” entities in a wrong pose, as explained above. Moreover, knowing that all the entities are arranged in a very specific relationship to one another (mouth under nose under eyes) - is a much stronger signal for the existence of a face, compared to just knowing they are there.
- Inefficient representation that leads to ineffective learning - instead of having a small canonical set per entity + pose information, every pose of the entity is modeled separately. That leads to a huge training set, which is orders of magnitude larger than what’s required for a human brain to learn the same classification / recognition.
Note : Write your oprnion in comment box to improve the post and also to get better understanding to other reader .
0 Comments:
Post a Comment